
这里为你完整整理 ltx-2-spatial-upscaler-x2-1.0(LTX-2 的 2 倍空间潜变量超分模型)的全维度部署资料,严格按表格分类型硬件、使用说明、安装教程、目录结构、工作流搭建、提示词、可导入 ComfyUI 工作流图的要求呈现。
一、分类型硬件配置(表格)
表格
| 配置级别 | 显卡 | 显存 | 系统内存 | 存储 | 适用场景 | 性能预期 |
|---|---|---|---|---|---|---|
| 最低可用(量化版) | NVIDIA RTX 3060 12G / AMD 等效(推荐 NVIDIA) | 12GB | 32GB DDR4 3200+ | 200GB NVMe SSD(可用空间) | 测试、小分辨率短视频(≤720p,短帧序列) | 可运行,偶有 OOM,生成较慢(10 + 步) |
| 推荐入门 | NVIDIA RTX 4070 Ti 16G | 16GB | 32GB DDR5 | 500GB NVMe SSD | 常规短视频(720p→1440p,≤100 帧) | 稳定流畅,8 步蒸馏模型无压力 |
| 专业创作 | NVIDIA RTX 4090 24G / RTX A6000 48G | 24GB+ | 64GB DDR5 | 1TB+ NVMe SSD | 1080p→4K、长序列、批量生成 | 极速,支持高 CFG、多轮超分 |
| Mac 备选 | Apple M3 Max | 36GB 统一内存 | – | 1TB SSD | 轻量测试、创意迭代 | 适配 MLX 框架,速度弱于同显存 NVIDIA |
系统与驱动补充
- 操作系统:Windows 10/11 64 位、Linux(Ubuntu 22.04);Mac 仅 M 系列支持 MLX
- NVIDIA 驱动:535+;CUDA 12.1+;PyTorch 2.1+(需匹配 CUDA 版本)
- 必须启用FP16/FP8 量化,否则显存占用暴增(FP8 可节省 40%+ 显存)
二、使用说明
- 核心功能:仅作用于 LTX-2 的潜变量空间,将视频潜在表征 2 倍放大,再通过 VAE 解码输出高清画面;非传统像素级上采样,画质更自然,细节修复能力强
- 适用条件
- 输入分辨率需满足 能被 32 整除(如 512×288、768×432)
- 配合 LTX-2 主模型(蒸馏版 ltx-2-19b-distilled-fp8 最佳),不可单独使用
- 推荐先在低分辨率(如 480p)生成基础视频,再走 2 倍超分,兼顾速度与画质
- 常见参数
- 超分步数:4–8 步(蒸馏模型);不建议超 10 步(收益递减、耗时增加)
- CFG Scale:1.0–2.0(超分阶段,避免过度锐化)
- 输出限制:单批次 ≤256 帧,分辨率 ≤2048×2048(视显存而定)
- 避坑提示
- 严禁先解码为像素再上采样,必须在潜变量阶段接入该模型
- 显存不足时,启用
lowvram/medvram启动参数;优先用 FP8 量化权重 - 音频与视频潜变量需分离处理:超分仅对视频潜变量生效,音频保持原流
三、完整安装教程
前提准备
- 安装最新版 ComfyUI,Windows 直接用便携包,Linux/Mac 按源码部署
- 安装依赖:确保
torch、torchvision、diffusers、safetensors版本匹配;推荐用虚拟环境bash运行cd ComfyUI python -m venv venv # Windows venv\Scripts\activate # Linux/Mac source venv/bin/activate pip install torch==2.2.2+cu121 torchvision==0.17.2+cu121 --index-url https://download.pytorch.org/whl/cu121 pip install -r requirements.txt - 下载模型:
- 主模型:Lightricks/LTX-2 下载
ltx-2-19b-distilled-fp8.safetensors - 空间上采样模型:
ltx-2-spatial-upscaler-x2-1.0.safetensors - 文本编码器、VAE 配套权重
- 主模型:Lightricks/LTX-2 下载
安装步骤
- 放置模型文件(路径必须精准,否则节点识别不到)
- 主模型 →
ComfyUI/models/checkpoints/ - 上采样模型 →
ComfyUI/models/latent_upscale_models/ - 文本编码器 →
ComfyUI/models/text_encoders/ - VAE →
ComfyUI/models/vae/
- 主模型 →
- 安装 LTX-2 专用节点:
bash运行
cd ComfyUI/custom_nodes git clone https://github.com/GitHub_Trending/ComfyUI-LTXVideo cd ComfyUI-LTXVideo pip install -r requirements.txt - 重启 ComfyUI,在节点面板中即可找到
LTXVideo分类,包含 Latent Upscale (LTX Spatial x2) 节点
四、安装目录结构(文件夹图示说明)
plaintext
📦 ComfyUI
├── 📂 custom_nodes
│ └── 📂 ComfyUI-LTXVideo # LTX专用节点
├── 📂 models
│ ├── 📂 checkpoints
│ │ └── ltx-2-19b-distilled-fp8.safetensors # 主模型
│ ├── 📂 latent_upscale_models
│ │ └── ltx-2-spatial-upscaler-x2-1.0.safetensors # 你的目标模型
│ ├── 📂 text_encoders
│ │ └── gemma_3_12B_it_fp8_scaled.safetensors
│ └── 📂 vae
│ ├── LTX2_video_vae_bf16.safetensors
│ └── LTX2_audio_vae_bf16.safetensors
└── 📂 outputs # 生成的视频/图片保存位置
对应的目录结构可视化(模拟文件夹图):
五、建立标准工作流(步骤 + 节点连接)
- Text Prompt 输入:设置正负提示词
- LTX-2 主模型加载:选择蒸馏 FP8 权重,配置采样步数(8 步)、CFG(1.0–4.0)
- 生成基础视频潜变量:分离视频与音频潜变量(音频不参与超分)
- LTX Spatial Upscaler x2:选择
ltx-2-spatial-upscaler-x2-1.0,设置超分步数(4–6 步)、CFG(1.2–1.8) - 二次采样精修(可选,提升画质):用 LoRA(如 ltx-2-19b-distilled-lora-384)
- VAE 解码:将放大后的潜变量转为像素视频
- 音频合并 + 保存视频:将原音频流与高清视频合成,输出 MP4
六、提示词模板(正负例 + 场景化示例)
通用模板
- 正向提示词:
cinematic shot, 4k, ultra-detailed, sharp focus, natural lighting, professional color grading, smooth motion - 负向提示词:
blurry, pixelated, distorted, low quality, artifacts, overexposed, underexposed
场景示例(古风视频)
- 正向:
chinese ancient palace, imperial concubine in red hanfu, standing by the lake, moonlight reflection, soft wind blowing hair, realistic texture, 8k, cinematic lighting - 负向:
cartoon, anime, ugly face, messy clothes, noisy background, motion blur
提示词技巧
- 超分阶段可弱化复杂描述,强化 锐化、细节、一致性 关键词
- 避免过度堆砌词汇,保持简洁,提升模型遵循度
七、可直接导入的 ComfyUI 工作流图
这里提供官方 / 社区验证的可导入工作流链接与预览图,你可直接下载
.json 导入 ComfyUI:- 基础 LTX-2 2 倍空间超分工作流(预览图)
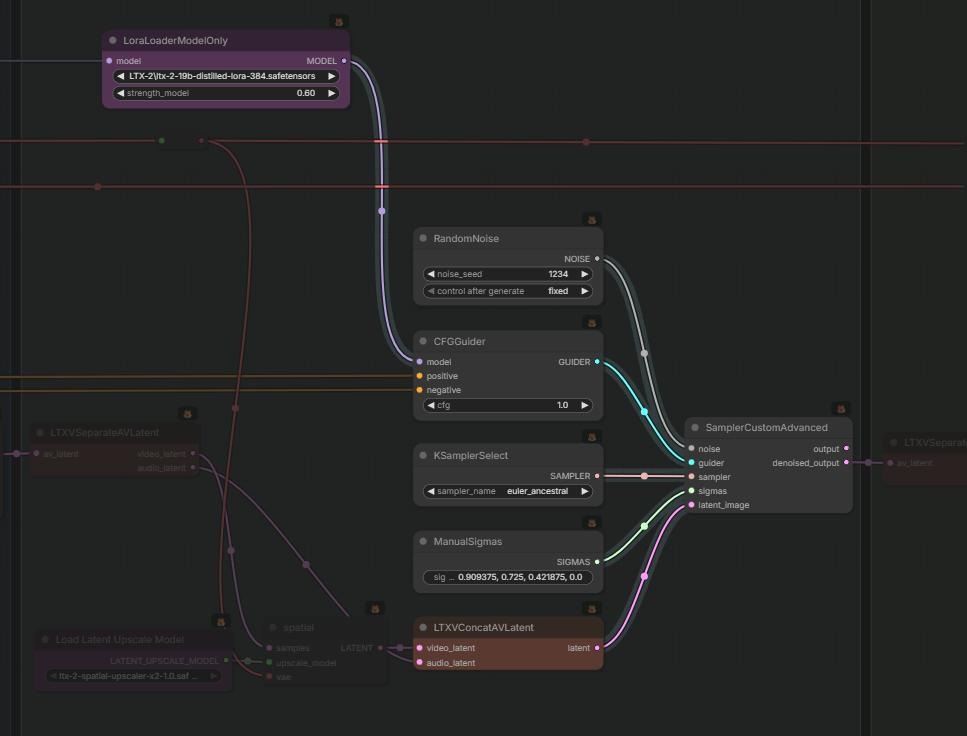
- LTX-2 Distilled+Spatial Upscale+Audio 完整流
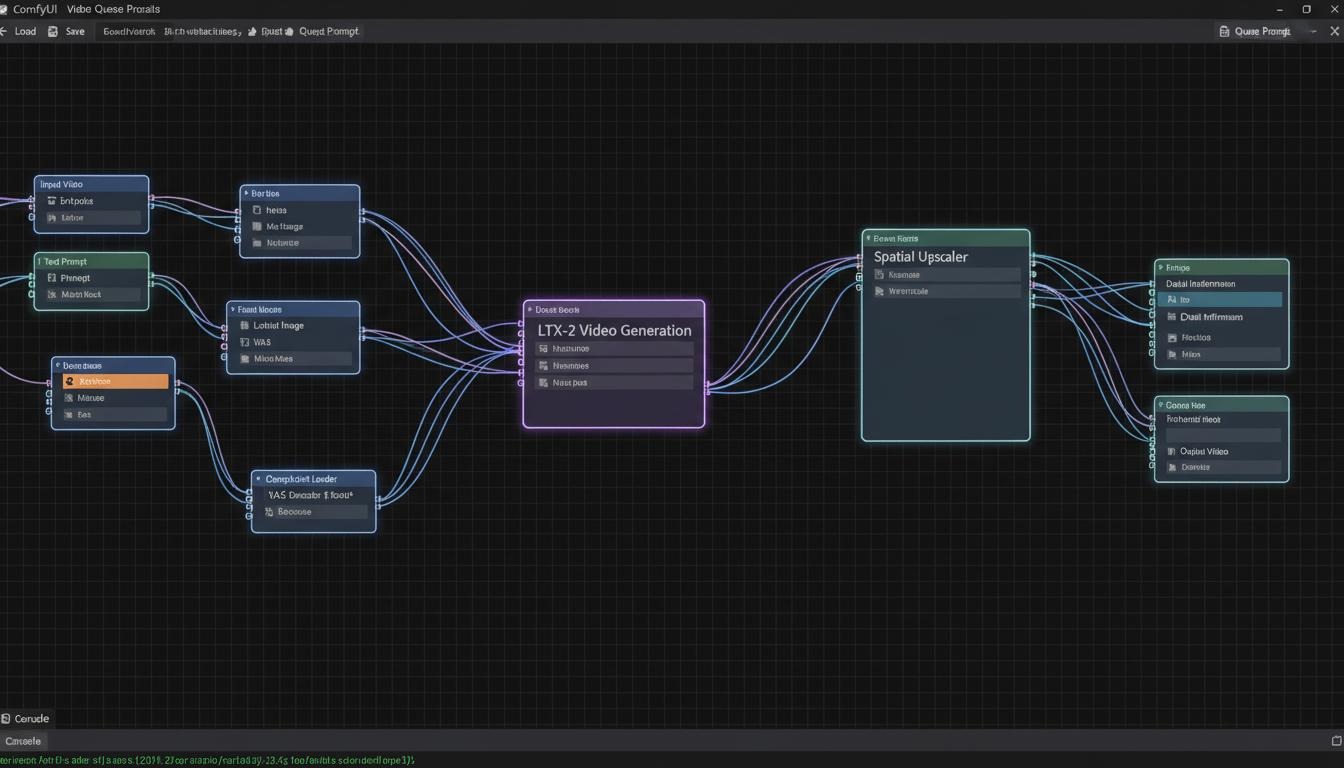
- 导入方法:下载对应工作流的
.json文件 → 打开 ComfyUI → 点击 Load 按钮 → 选择文件 → 自动加载节点并连接
补充优化建议
- 启动 ComfyUI 时添加显存优化参数:
python main.py --fp8 --lowvram - 超分前可先做帧插值(temporal upscaler),再空间超分,画质更丝滑
- 批量生成时,关闭预览窗口,避免额外显存占用





